
����˫���ָ����뷨�� ������ָ�Ϊ������ɾ�������ָ�����ѡ560���������롢ţ��������ָ����ԣ�Ҳ��Ϊ����������뷨������ĩ���ʶ��ָ����з��࣬Ҳ��Ϊ����������뷨�����ն��ʡ���ʡ�������ŵ�,ȫ�����ȫ�¹���ȫ���ָ���ȫ��ʶ���룬����˫���ָ����뷨��ѧ�����á��üǡ������١�����졢Ч�ʸߣ������ִ��˶����뷨Ҫ��
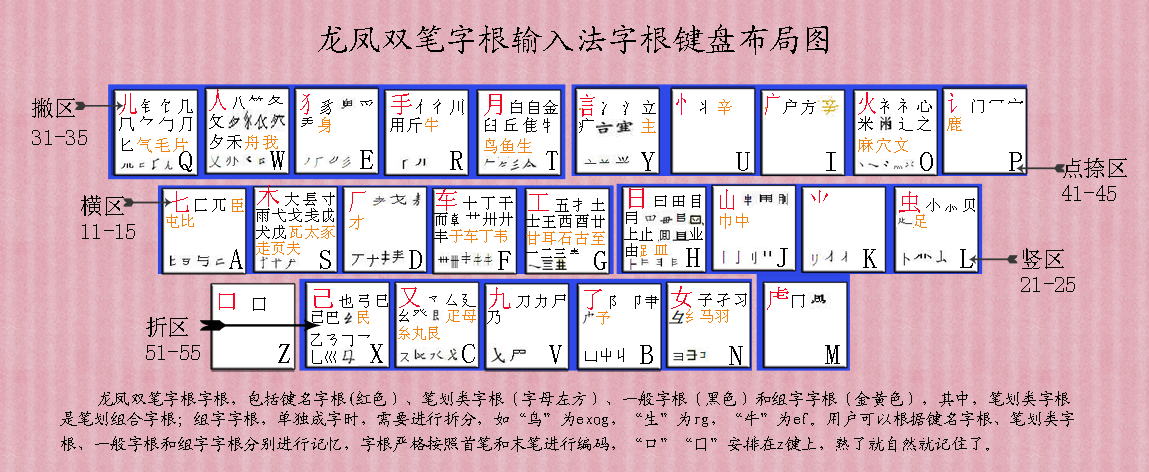
����˫���ָ����뷨�ָ��ϸ��ձ�������ָ������ױʺ�ĩ�ʽ��б��룬����������˫���ָ��ı������ͼ��
����˫���ָ��ָ������������ָ����ʻ����ָ���һ���ָ��������ָ������У��ʻ����ָ��DZʻ�����ָ��������ָ�����������ʱ����Ҫ���в�֣��硰��Ϊexog�����㡱Ϊqhg��������Ϊrg����ţ��Ϊef���û����Ը��ݼ����ָ����ʻ����ָ���һ���ָ��������ָ��ֱ���м��䣬Ҳ���������ǿھ����м��䡣Ҳ���Բ����м��䣬�ָ������ױʺ�ĩ�ʽ��б��룬���˾���Ȼ�ͼ�ס�ˡ�
��
����˫���ָ��ָ�����ͼ�����������ú����û�������
�� ����˫���ָ����뷨��ʶ���� �ж��ְ汾��һ��������˫���ָ����뷨ʶ��������һ�����������ʶ���룬����������ͬ�ġ�����˫���ָ����뷨��ʶ�������� ���ֵĴαʺʹ�ĩ�ʽ��б��룬����������˫���ָ���ʶ�������ͼ������˫���ָ���ʶ�������ͼ������˫���ָ��ı��������ͬ���û�����Ҫ�������������ݡ�
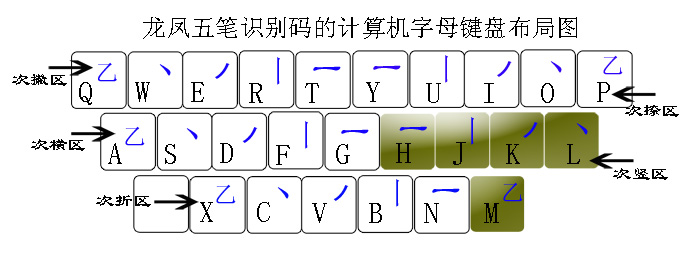
���պ�����д��˳����ɢ���ԣ����Բ��Ϊһ�������ָ�������ǰ��ĩһ������ָ�ȡ�롣���������룬���Ը�����Ҫ������ʶ���롣���Ӳ�������������룬���Ը�����Ҫ����һ����������z����Ϊ���롣
���磺���Ρ��ı���Ϊ��a��,����ʶ�����Ϊ��an��,��������ָ���ʶ���Ϊ��anz����
����˫���ָ����뷨������ʹ���������ʶ�������������������ʶ��������ͼ��
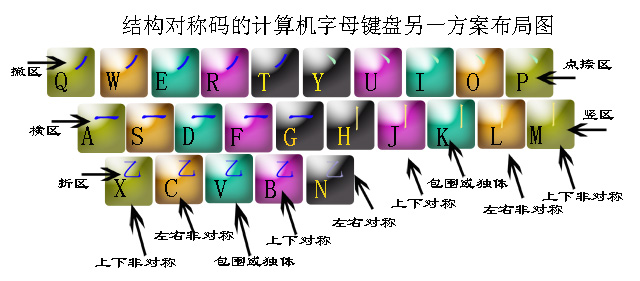
����ʱ��뷽�����и�����Դ����µ�ʶ���뷽�����÷��������ݺ��ֽṹ����Ϊ���ҽṹ�����½ṹ�����������Χ�ṹ��Ȼ������ҽṹ�����½ṹ�ķǶԳƺ��֣�������������������λ���� ��
�����ȿ��Ǹú��ֵ����һ�ʣ�ĩ�ʣ����Ӷ�ȷ��Ҫ�ӵ�ʶ�������ڵ������ᡢ����Ʋ���ࡢ�ۣ����ٿ��Ǹú��ֵĽṹ�����ң����£��Ӻϣ����Ӷ�ȷ������ʶ������������λ����һλ���ڶ�λ������λ����
�����磺�㣨�ָ�����TJ��������������³������ǡ��á��֡�Ϊ�˴�����㡱������Ҫ��ʶ���롣
�������ڡ��㡱��ĩ��Ϊ��һ�����ᣩ���������ȿ���ȷ������ʶ�����ں������ҡ�
����������ڡ��㡱�ֵĽṹΪ�������͡������Կ���ȷ��ʶ����Ӧ���Ǻ����ĵڶ�������F����
�������ԡ��㡱�������ı���Ϊ��TJF��
��ʶ�����ԭ��:
����1��ֻ��С���ĸ��ָ��ĵ��ֲ���Ҫ��ʶ���롣Ҳ�����ָ��֣��ȴ������ڵļ����ٰ���д˳������ĵ�һ�ʡ��ڶ��ʺ����һ�ʣ��������֣������������ڵļ����£���������Ҫ��ʶ���룬����һ���������������ĸ����ϵ��ָ����硰�ҡ���د���У��ң�ؼ��د������������岡������֡�һ���ˣ�ؼؼ�����Ͳ�����Ҫ��ʶ���롣
����2�����ʻ���һ��ح��د��ؼ���ң��������ָ��ཻ������ʱ��Ӧ�ðѸ��ֿ������ӺϽṹ��
�����磺������������ָ�Ϊ��د��֮�������ڵ��ʻ���د���롰֮�������������������뿴�����ӺϽṹ���Ӷ�ȷ��ʶ����Ϊ��I"
�������磺���硰������ָ�Ϊ��������ȥ�����һ�ᣩ��د�������ڵ��ʻ���د���롰����������Ҳ���뿴�����ӺϽṹ���Ӷ�ȷ������ʶ����Ϊ��E��
�������磺������������ָ�Ϊ���棬د���ڣ������ڵ��ʻ���د���롰�桱�ཻ�����ԡ�����Ҳ���뿴�����ӺϽṹ���Ӷ�ȷ����ʶ����Ϊ��D��
������������ʻ����ָ���������Ҳ���ཻ���ͱ�������������
�����磺�����������½ṹ�����ɡ������ҽṹ��
����3���ָ����ָ������������½ṹ���ָ����ָ��ཻ���ӺϽṹ��
�����磺�������š������½ṹ���������������Ϊ�ӺϽṹ��
����4�����������ȡ�������ȫ��Χ�����Χ�ṹ�ĺ��֣����ǵ�ĩ�ʱ���ȡ����Χ�ṹ�����һ�ʣ���������Щƫ����ĩ�ʡ��˾���Ϊ�����ʶ�����Ч�ʣ����������ʡ�
�����磺����LPK����Բ��LKMI��
����5�����š�ذ�����������ĸ����֣��ڲ���ʶ��ʱ����ĩ��ͳһ�涨Ϊ���ҡ����ۣ���
ʶ�������ϸ���ݿɲ���
���պ�����д��˳����ɢ���ԣ����Բ��Ϊһ�������ָ�������ǰ��ĩһ������ָ�ȡ�롣���������룬���Ը�����Ҫ������ʶ���롣���Ӳ�������������룬���Ը�����Ҫ����һ����������z����Ϊ���롣
���磺���Ρ��ı���Ϊ��a��,����ʶ�����Ϊ��an��,��������ָ���ʶ���Ϊ��anz����
��������˫���ָ��ָ���ֺ�����ʵ��������˫��ʶ������
�������ʹ������˫���ָ����뷨ʶ�������ָ���ֺ�����ʵ��������˫���ָ��ָ���ֺ�����ʵ�����������ʶ������Ҳ�����Ƶģ����պ�����д��˳����ɢ���ԣ����Բ��Ϊһ�������ָ�������ǰ��ĩһ������ָ�ȡ�롣�����Ը�����Ҫ������ʶ������Ϊ���롣
1.����Ϊ���ָ�ʱ�������Ը�����Ҫ�� ����ʶ������ָ���ʶ����Ϊ���룬���磺
l ���⡱Ϊ���ָ��֣�ȡ��Ϊ��b��������ʶ�����Ϊ��bm����
l ���ࡱΪ���ָ��֣�ȡ��Ϊ��b��������ʶ�����Ϊ��bm����ȡ�ָ���ʶ��Ϊ��bmz����
l ������Ϊ�����ָ��֣���Ҫ���в��Ϊ���ߡ�ʮ����ȡ��Ϊ��af����
l ���ȡ�Ϊ�����ָ��֣���Ҫ���в�֣�ȡ��Ϊ��aq����
2.���ָ����µ��֣�ȡ���ֵIJ�ֵ��ָ����룬�����Ը�����Ҫ�� ����ʶ������Ϊ���룬���磺
l ���ۡ��֣��ɲ��Ϊ���п������ָ���ȡ��Ϊ��gz��,����ʶ�����Ϊ��gzm����
l ���ơ��֣��ɲ��Ϊ��ڥ�W�������ָ���ȡ��Ϊ��pqt�� ,����ʶ�����Ϊ��pqtn����
l �������֣��ɲ��Ϊ����Ϧ�������ָ���ȡ��Ϊ��uws��,����ʶ�����Ϊ��uwsf����
l �����֣��ɲ��Ϊ��ֹذľ�����ָ���ȡ��Ϊ��hqs��,����ʶ�����Ϊ��hqsd����
3.���ָ����ϵ��֣�ȡ���ֵ�ǰ���������һ���ָ��ı��롣
l ���֣��ɲ��Ϊ���ڷᵶ�������ָ���ȡ��Ϊ��yfvo����
l ����֣��ɲ��Ϊ���⺿�ҳ�����ָ���ȡ��Ϊ��pwzs����
l ���ԡ��֣��ɲ��Ϊ��ڥ�]ڢ�ڶ������ָ���ȡ��Ϊ��pkpq����
l �������֣��ɲ��Ϊ����ܳ�����ˁ]�����ָ���ȡ��Ϊ��zfhx����
l �������֣��ɲ��Ϊ������һ��һ�������ָ���ȡ��Ϊ��xggh����
4.���ֲ���ָ��ļ���Ҫ�㡣
l �ָ����պ��ֱ�˳��д˳����в�֣����ָ���˳���淶���硰�Ρ������족����߮�����������ȣ������ָ����ױʣ������ָ��IJ��˳��ҽ������Ϊ��ats��������������Ϊ��zats������ҽ������Ϊ��zgo����
l �����ð�����ɢ��ֱ��Ϊ����Խ�ӽ���ȻΪ������ɢ�����IJ�����ȼ�����ɢ���롢Χ����Σ��ཻ������ȡ�����ȣ���Ԫ����Ϊԭ������Ϊ��rqhw�������족����Ϊ��iso����
| Q �� | W �� | E �� | R �� | T �� | Y �� | U �� | I �� | O Ϊ | P �� |
| A �� | S �� | D �� | F �� | G һ | H �� | J ˮ | K �� | L ʡ | |
| Z �� | X �� | C �� | V չ | B �� | N �� | M ͬ |
�������
|